

Scritto da Alfredo Visconti Presidente ANDIP
Parte ufficialmente il nuovo registro delle opposizioni ed è strutturato “talmente bene” da risultare molto attento al trattamento dei dati personali infatti subito dal primo giorno ha preferito andare giù ed esporre il più classico degli errori, il mitico 404 pagina non trovata, pur di non prendere dati personali degli utenti.
Nonostante tutto oggi sul sito troviamo l’articolo che dichiara, e non abbiamo motivo di no crederci, che già il primo giorno il nuovo registro delle opposizioni ha visto l’iscrizione di 205 mila utenti.
Ma disservizi a parte oggi siamo riusciti ad iscriverci come evidenziato dalla schermata sotto riportata, e quindi a partire da oggi possiamo verificare, e lo faremo molto scrupolosamente da una parte come il mercato si comporterà rispetto a questa novità, dall’altra come i servizi preposti al controllo opereranno su eventuali disservizi.
La grande novità sta nel fatto che il nuovo registro delle opposizioni prevede i controlli anche per cellulari dando quindi la possibilità di opporsi al telemarketing e di conseguenza non ricevere più telefonate sgradite sul mobile.
Di seguito vediamo la mail che arriva dal sito del RPO
|
10:01 (35 minuti fa) | |||
|
||||
Gentile Utente,
la tua richiesta di iscrizione al Registro pubblico delle opposizioni per uno o più numeri di telefono indicati e/o per uno o più indirizzi di posta cartacea associati negli elenchi telefonici pubblici è stata presa in carico.
Trascorso un giorno lavorativo dalla richiesta, per conoscere l’esito dell’operazione puoi chiamare dal numero di telefono per cui hai richiesto l’iscrizione il nostro numero verde 800 957 766 dal fisso o il numero 06 42986411 dal cellulare; in alternativa puoi accedere a “Gestisci iscrizione” tramite web.
Ti è stato assegnato un Codice Registro associato all’operazione di iscrizione valido 90 giorni per gestire l’iscrizione tramite le modalità web ed email. Se non lo hai memorizzato nel corso della compilazione della richiesta di iscrizione oppure è scaduto, è possibile generarne uno nuovo chiamando dal numero di telefono interessato i numeri RPO sopra indicati.
Con l’occasione, ti ricordiamo che:
- la richiesta di iscrizione viene gestita entro un giorno lavorativo e diventa pienamente efficace entro 15 giorni per il RPO Telefonico e 30 giorni per il RPO Postale.
- l’iscrizione al RPO annulla i consensi al marketing telefonico e alla cessione del numero di telefono precedentemente rilasciati per campagne promozionali, tessere per la raccolta punti, la scontistica e la fidelizzazione;
- la revoca dei consensi ha efficacia sia sulle chiamate effettuate con operatore umano sia su quelle automatizzate;
- dopo l’iscrizione al servizio è possibile ricevere solo chiamate autorizzate nell’ambito di contratti in essere o cessati da non più di 30 giorni (per esempio del settore telefonico ed energetico) oppure contatti da parte di operatori a cui hai rilasciato apposito consenso successivamente alla data di iscrizione o di ultimo rinnovo dell’iscrizione.
Per maggiori informazioni ti invitiamo a visitare il sito www.registrodelleopposizioni.it.
Cordiali saluti,
Notiamo un passaggio fondamentale degno di nota sul quale avremo modo di effettuare anche qualche verifica.
Il secondo punto dice che questa iscrizione annulla i consensi al marketing telefonico e alla cessione del numero di telefono anche se precedentemente rilasciati
Ma cosa ancor più importante l’ultimo punto che spiega che sarà possibile ricevere telefonate solo per consensi rilasciati dopo questa iscrizione.
Questo passaggio mette in luce un punto chiaro da sempre, ma sul quale in tanti hanno giocato per far della privacy quello che più ritenevano opportuno. Il consenso deve essere salvato e verificabile almeno durante la sua esistenza.
Adesso nasce il dubbio Alcuni dubbi storico e sempre esistito su come si comporteranno gli operatori di telemarketing che operano con base all’estero e quindi fuori della dalla portat della giurisdizione italiana, ma in proposito il MISE ha dichiarato che questa regole vale anche per i call center stranieri.
Scritto dall’Avvocato Cristina Mantelli Delegato ANDIP-Bologna Componente del Comitato Scientifico ANDIP
Gli archivi digitali: la cancellazione sicura dei dati
Gli archivi digitali rappresentano il patrimonio informatico di ogni impresa. Proteggerli è importante non solo per questioni di sicurezza ma anche perché esistono obblighi di legge. Si ricorda, fra gli altri, che GDPR contempla la cancellazione sia su richiesta degli interessati (art. 17) sia per “scadenza” dei termini di conservazione dei dati stessi (art. 13, comma 2, lettera a). Non ottemperare alla normativa e alle condizioni di sicurezza nelle operazioni di cancellazione/distruzione dei dati potrebbe portare a sanzioni pecuniarie contemplate dall’art. 83 fino a 20.000.000,00 euro o al 4% del fatturato mondiale annuo del gruppo imprenditoriale se superiore a 20 milioni.
Ad accentuare il problema della governance dei dati vi è poi l’ambiente cloud considerando che spesso non si detiene un controllo diretto, ma ci si avvale di spazi di terze parti; da ciò ne consegue che può sussistere anche l’eventualità che pur se distrutto dall’ambiente cloud, il dato continui a permanere, magari su copie di backup di cui il titolare non ha piena contezza.
Purtroppo, nella mentalità comune i dati, una volta svuotato il cestino, vengono considerati cancellati in maniera indelebile: niente di più errato! A volte possono essere ripristinati, in alcuni casi, persino dopo una formattazione.
Pertanto, i professionisti e le imprese quando decidono di dismettere dei dati devono avere adeguate procedure volte alla cancellazione definitiva e/o alla distruzione degli stessi.
Quali sono quindi gli strumenti tecnici a disposizione per la cancellazione definitiva dei dati?
Le principali modalità per la cancellazione/distruzione dei dati sono:
- La distruzione fisica irreversibile del supporto attraverso metodi che garantiscono che sia impossibile ricostituire il supporto stesso, magari perché viene triturato.
- La smagnetizzazione del supporto attraverso uno specifico macchinario denominato degausser
- La criptazione dei dati (fra l’altro l’art. 34 co. 3 del GDPR esonera dal comunicare all’interessato il data breach qualora sia stata applicata la cifratura)
- Il Wiping, una serie di sovrascritture dell’intero hard disk tramite apposite tecniche
Il Wiping è una procedura che rende impossibile il recupero dei dati. Esistono diversi software – secondo standard di sicurezza predefiniti – che si diversificano per i numeri di passaggi di sovrascrittura. Blancco e BitRaser sono due dei software più utilizzati e conosciuti sul mercato che consentono anche di certificare il processo.
In buona sostanza è certamente fondamentale avere policy, processi e procedure chiaramente definiti che permettano di avere una roadmap dei dati.
All’uopo si ricorda che il principio di accountability impone al titolare/responsabile di dimostrare che sta effettuando un trattamento in linea con il GDPR.
Scritto da Alfredo Visconti Presidente ANDIP
E’ ormai di uso comune la definizione delle informazioni personali come il nuovo petrolio, per evidenziare il valore economico e di conoscenza che questi dati, anche grezzi, hanno come merce di scambio in un mercato spesso invisibile agli occhi degli utenti finali.
Il valore di questi dati per singolo set di dati valgono in media pochi euro, ovviamente però il vero valore, anche qui economico e conoscitivo, sta nella quantità e qualità, le aziende acquistano database dai data broker in blocchi di migliaia, se non milioni di dati elaborati.
Ancora a qualcuno potrebbe nascere spontanea la domanda sul perché comprare questi set di dati. La risposta è di una semplicità disarmante ma soprattutto sta nelle attuali regole di mercato, tutto dipende da cosa ci si vuole fare, il loro vero valore ed il loro peso rispetto al mercato sta nella capacità di descrivere persone e gruppi di persone prevedendone comportamenti, caratteristiche ed usi effettuando quindi una profilazione il più attendibile possibile. Come è facile intuire maggiori sono i dati di cui si entra in possesso maggiore sarà l’attendibilità di questi stessi dati facendo si che la precisione in investimenti sia sempre maggiore.
Solo per facilitare la comprensione fra la raccolta e l’utilizzo poi di terze parti basti pensare a Google, Facebook, linkedin e cosi via che effettuano una grande raccolta di dati proprietari anche al fine di offrire ai propri, e non solo, inserzionisti una segmentazione accurata ed efficace, che permette di creare campagne di marketing o semplici visualizzazioni di banner, specifici e dettagliati per quel determinato utente. Per ampliare il discorso ed uscire dalla gestione dei social network, basti pensare che lo stesso ragionamento appena sviluppato e valido anche per altri settori come ad esempio del settore assicurativo, aziende di credito, aziende sanitarie che nello specifico utilizzano i dati per prevedere il livello di rischi e configurare in modo preciso il cliente.
Spieghiamo che abbiamo parlato di broker di dati che è colui che compra e rivende dati offrendo un servizio fondamentale per chi acquista, in questo caso infatti i dati che si acquistano non sono grezzi, ma aggregati ed elaborati in modo da poter essere utilizzati immediatamente. Praticamente chi acquista non acquista dati ma acquista informazioni.
Per capire meglio la differenza fra dato ed informazione basta un semplice esempio:
dati 19652412, M32A20, MAIL questi sono i dati cosi come vengono letti da una interrogazione su un database. La lettura non fa trapelare nulla chi li legge non sa interpretarli ne quindi tantomeno dargli un significato.
Informazioni lavorando sui dati prima segnalati e attraverso le opportune conoscenze si può ottenere la traduzione ed il dignificato di quei dati, quindi l’informazione e nello specifico vediamo che abbiamo
Mail per indicare cosa utilizzare come username
1965242 sono i dati da indicare come password
M32A20 indica la matricola del lavoratore da utilizza come ulteriore componente della password.
Siamo passati da valori insignificanti al valore di una informazione ben precisa.
Stabilito adesso ove mai ve ne fosse bisogno l’importanza dei dati trasformati in informazioni, chi li raccoglie, chi li vende e chi li usa vediamo come anche il più attento di noi dissemina dati personali, anche sensibili sulla rete, lasciano questi alla mercè di tutti.
Per capire ed immaginare come tutto succede rendiamoci conto che di dati personali ne condividiamo ogni giorno in grande quantità anche e soprattutto a prescindere spesso dalla nostra volontà di comunicarli. Purtroppo il famoso principio di proporzionalità nella raccolta dei dati resta ancora per tante aziende un eufemismo al quale l’utenza si è dovuta piegare se voleva il servizio richiesto. In una giornata tipo rilasciamo dati a causa di dati di registrazione su siti web, compagnie telefoniche, pagamenti bancomat o con carte di credito, richieste di fatture elettroniche, servizi Internet per poi continuare quando siamo in movimento con dati rilasciati in strutture alberghiere, pedaggi autostradali, servizi gps e si potrebbe continuare …. Il tutto diventa molto pericoloso, ma soprattutto senza nessun controllo o quasi se pensiamo che stiamo parlando di dati che vengono comunicati attraverso smartphone e telefoni purtroppo spesso senza che neanche ce ne accorgiamo.
Adesso dobbiamo ragionare seriamente sul come questi dati vengono messi in sicurezza al momento dell’utilizzo, precisando subito che questo livello di attenzione da i suoi risultati solo se capiamo che oltre i software di protezione occorre determinare delle regole comportamentali precise.
Ripartiamo quindi dalle informazioni che vengono raccolte ad esempio tramite i nostri telefoni cellulari:
- Dati sulla posizione tramite la geolocalizzazione
- Dati di navigazione tramite i cookie
- Registrazione su app e siti
- Invio di mail con e senza allegati
- Dati e file personali sul telefono mediante le autorizzazioni delle app
Non possiamo certo vederle tutte nel dettaglio queste attività però spendiamo qualche parola su qualche caratteristica importante di queste 5 tipologie.
Ad esempio tutte e 5 le possibilità appena citate offrono servizi gratuiti, questo perché in un mondo come questo di oggi dove tutto si paga senza questa gratuità molti di noi non rilascerebbero i propri dati.
A titolo di esempio la geolocalizzazione – La geolocalizzazione è la tecnologia GPS (dall’inglese Global Positioning System, ovvero “sistema di posizionamento globale”) integrata nei dispositivi mobili (Android, iOS e Windows Phone) che permette di determinare la posizione geografica di una persona in base, ad esempio, al suo smartphone. Tanto ciò detto tradotti in soldoni chi raccoglie i nostri dati sa sempre dove ci troviamo, se abbiamo percorsi particolari, con che cadenza effettuiamo determinati giri e lavorando di immaginazione ……
Oppure le autorizzioni sulle app dove senza nemmeno accorgercene concediamo l’accesso ai nostri file, alle nostre foto e alla rubrica del telefono, le app scaricano sui propri server tutte le questa mole di informazioni, che poi vengono, elaborate e rivendute come precedentemente detto.
Da quanto appena detto tiriamo le fila e cerchiamo di proteggerci attraverso alcuni passaggi non necessariamente informatici, come:
- Prestare la dovuta attenzione alle autorizzazioni delle app, sia in fase di registrazione sia in fase di utilizzo.
- Verificare la proporzionalità delle informazioni richieste e delle autorizzazioni che si concedono quando si utilizzano servzi online, se sono richieste troppe informazioni rispetto al servizio meglio soprassedere.
- Accertarsi che nelle mail inviate e ricevute il testo ed eventuali file allegati siano adeguatamente protetti si pensi che il Garante a più volte esplicitato che “L´acquisizione e l´utilizzazione di indirizzi e-mail a scopo promozionale, senza la previa acquisizione di un informato consenso degli interessati, integra un ripetuto illecito trattamento di dati personali che giustifica la sospensione temporanea di ogni trattamento, ad eccezione della mera conservazione dei dati personali detenuti (provvedimento di blocco temporaneo adottato nei confronti di una società convenuta in un procedimento avente ad oggetto l´invio di e-mail promozionali non richieste, dal quale sono derivati ulteriori accertamenti d´ufficio)” .
- Utilizzare una VPN verificandone le caratteristiche di protezione.
È importante essere consapevoli di questo fenomeno di costruzione delle informazioni partendo dai dati, innanzitutto per immunizzarci contro la comunicazione persuasiva di chi utilizza i nostri dati, ma anche per capire il valore delle nostre informazioni.
Insomma, i dati servono alle grandi aziende per analizzare attraverso seri e precisi programmi di profilazione chi siamo, dove andiamo, come spendiamo, in cosa spendiamo e con che frequenza compiamo azioni importanti per il mercato.
E se decidiamo di non dare importanza ai nostri dati ed a come li disseminiamo dobbiamo rassegnarci al fatto che con queste informazioni, il marketing digitale e quello diretto diventano potenti armi di persuasione, che riescono a tracciarci e raggiungerci nei momenti in cui è più probabile che prenderemo in considerazione il loro messaggio pubblicitario.
Scritto da F. Calì e S. Gorla
_______________________________
Vista la crescente dipendenza della vita quotidiana e delle economie dalle tecnologie digitali, i cittadini sono sempre più esposti a gravi incidenti informatici. Per far fronte alle sfide crescenti, l’Unione Europea ha intensificato le sue attività nel settore della sicurezza informatica, promuovendo un ecosistema cibernetico sicuro e affidabile.
Nel 2016 infatti l’Unione ha adottato le sue prime misure nel settore della cibersicurezza attraverso la direttiva (UE) 2016/1148 del Parlamento europeo e del Consiglio sulla sicurezza delle reti e dei sistemi informativi, la così detta Direttiva NIS (Network and Information Security). Questa è stata recepita dall’Italia con il decreto legislativo n.65/2018 pubblicato sulla Gazzetta Ufficiale il 9 giugno ed effettivo dal 24 giugno.
La direttiva è volta a migliorare le difese delle infrastrutture critiche degli Stati membri, puntando sulla intelligence e prevenzione per raggiungere un adeguato livello di sicurezza cibernetica e di resilienza dei sistemi critici nazionali. L’obiettivo è quello di creare misure volte a garantire un livello comune elevato di sicurezza delle reti e delle informazioni che sia uniforme in tutta l’Unione europea. Ciò, attraverso l’adozione di misure tecniche e organizzative che consentano di ridurre i rischi e l’impatto degli incidenti informatici. In quest’ottica, la Direttiva si sviluppa su tre piani:
- promuovere la cultura della gestione del rischio e della segnalazione degli incidenti tra i principali attori economici, in particolare tra gli operatori che forniscono servizi essenziali per il mantenimento di attività economiche e sociali, così come tra i fornitori di servizi digitali;
- migliorare le capacità nazionali in materia di sicurezza cibernetica;
- rafforzare la cooperazione in questo settore a livello nazionale e in ambito europeo.
L’applicazione della direttiva NIS riguarda principalmente le aziende che verranno identificate come Operatori di servizi essenziali (OSE) o Fornitori di servizi digitali (FSD).
Tanto gli OSE che gli FSD sono chiamati ad adottare misure tecniche e organizzative adeguate e proporzionate alla gestione dei rischi e a prevenire e minimizzare l’impatto degli incidenti a carico della sicurezza delle reti e dei sistemi informativi, al fine di assicurare la continuità del servizio. Hanno inoltre l’obbligo di notificare, senza ingiustificato ritardo, gli incidenti che hanno un impatto rilevante,rispettivamente sulla continuità e sulla fornitura del servizio, al Computer Security Incident Response Team (CSIRT) italiano, informandone anche l’Autorità competente NIS di riferimento.
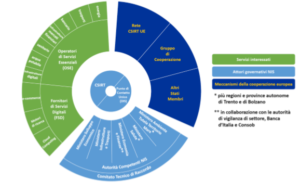
I soggetti giuridici non identificati come OSE e che non sono FSD possono inoltrare al CSIRT notifiche volontarie degli incidenti che abbiano un impatto rilevante sulla continuità dei servizi da loro erogati. Ciò poiché l’intento della Direttiva NIS e del relativo decreto di recepimento è quello di favorire la più ampia diffusione di una consapevole cultura nel campo della cybersecurity e di un conseguente accrescimento dei relativi livelli di sicurezza, anche attraverso un maggiore scambio di informazioni.
Il decreto 65/2018 resta molto fedele al testo della direttiva europea e identifica otto settori di intervento: energia, trasporti, banche, mercati finanziari, sanità, fornitura e distribuzione di acqua potabile, infrastrutture digitali, servizi digitali (quali motori di ricerca, servizi cloud e piattaforme di commercio elettronico).
Si prevede, inoltre, l’istituzione presso la Presidenza del Consiglio dei Ministri di un unico Computer Security Incident Response Team, detto CSIRT italiano, che andrà a sostituire, fondendoli, gli attuali CERT Nazionale (operante presso il Ministero dello Sviluppo Economico) e CERT-PA (operante presso l’Agenzia per l’Italia Digitale).
Gli operatori di servizi essenziali dovranno adottare misure tecnico-organizzative “adeguate” alla gestione dei rischi e alla prevenzione degli incidenti informatici. Il decreto specifica che nell’adottare tali misure gli operatori dovranno tenere in debita considerazione le linee guida che sono state recentemente predisposte dal Gruppo di Cooperazione. Le autorità competenti NIS potranno inoltre imporre l’adozione di misure di sicurezza specifiche, sentiti gli operatori di servizi essenziali.
Analoghi obblighi in materia di sicurezza sono previsti a carico dei fornitori di servizi digitali, i quali dovranno adottare misure tecniche-organizzative per la gestione dei rischi e per la riduzione dell’impatto di eventuali incidenti informatici.
Per l’adozione di tali misure i soggetti coinvolti possono utilizzare framework come quello elaborato dal NIST U.S. (l’Istituto Nazionale degli Standard e della Tecnologia), o la certificazione ISO 27001, quali soluzioni di best practice, allo scopo di valutare il loro livello di sicurezza IT e impostare obiettivi per migliorare le procedure utilizzate per proteggere i dati sensibili. I livelli del Cybersecurity framework (parziale, consapevole del rischio informatico, replicabile e adattivo) spiegano quanto deve essere profonda l’implementazione della sicurezza informatica e con riferimento alle categorie e sottocategorie, è possibile stabilire dove siano le lacune e scegliere i piani d’azione più adeguati per colmarle. La ISO 27001 adotta un approccio più ampio poichè la sua metodologia si basa sul ciclo Plan-Do-Check-Act (PDCA), ovvero costruire un sistema di gestione che non solo progetta e implementa la cyber security, ma mantiene e migliora anche l’intero sistema di gestione delle informazioni.
Tornando alla Direttiva NIS, in ossequio a quanto richiesto dall’Articolo 7, il decreto di recepimento prevede l’adozione di una strategia nazionale di sicurezza cibernetica da parte del Presidente del Consiglio dei Ministri. La strategia dovrà prevedere in particolare le misure di preparazione, risposta e recupero dei servizi a seguito di incidenti informatici, la definizione di un piano di valutazione dei rischi informatici e programmi di formazione e sensibilizzazione in materia di sicurezza informatica.
Così nel mese di luglio 2019 il nostro Paese ha visto, da un lato, la realizzazione e la diffusione delle Linee guida per gli OSE in ambito NIS e, dall’altro, lo “Schema di disegno di legge in materia di perimetro di sicurezza nazionale cibernetica”. Tutti questi interventi legislativi sembrerebbero tessere di un mosaico che si colloca in maniera coerente con l’evoluzione che ormai da tempo si sta ravvisando nello scenario nazionale e internazionale in tema di cyber security e sicurezza delle informazioni.
Il Consiglio dei Ministri ha infatti approvato proprio qualche giorno fa un disegno di legge in materia di perimetro di sicurezza nazionale cibernetica per assicurare un livello elevato di sicurezza delle reti, dei sistemi informativi e dei servizi informatici delle amministrazioni pubbliche, degli enti e degli operatori nazionali, pubblici e privati, da cui dipende l’esercizio di una funzione o servizio essenziale dello Stato per il mantenimento di attività civili, sociali o economiche fondamentali e dal cui malfunzionamento, interruzione, anche parziali, ovvero utilizzo improprio, possa derivare un pregiudizio per la sicurezza nazionale.
A questo scopo, il disegno di legge prevede:
- la definizione delle finalità del perimetro e delle modalità di individuazione dei soggetti pubblici e privati che ne fanno parte, nonché delle rispettive reti, dei sistemi informativi e dei servizi informatici rilevanti per le finalità di sicurezza nazionale cibernetica per i quali si applicano le misure di sicurezza e le procedure introdotte;
- l’istituzione di un meccanismo teso ad assicurare un procurement più sicuro per i soggetti inclusi nel perimetro che intendano procedere all’affidamento di forniture di beni e servizi ICT destinati a essere impiegati sulle reti, sui sistemi e per i servizi rilevanti;
- l’individuazione delle competenze del Ministero dello sviluppo economico – per i soggetti privati inclusi nel perimetro – e dell’Agenzia per l’Italia Digitale (AgID) – per le amministrazioni pubbliche;
- l’istituzione di un sistema di vigilanza e controllo sul rispetto degli obblighi introdotti;
- lo svolgimento delle attività di ispezione e verifica da parte delle strutture specializzate in tema di protezione di reti e sistemi nonché, per quanto riguarda la prevenzione e il contrasto del crimine informatico, delle Amministrazioni da cui dipendono le Forze di polizia e le Forze armate, che ne comunicano gli esiti.
Le conseguenze dell’ approvazione di questa legge saranno numerose: questo infatti potrebbe rappresentare il primo vero momento di diffusione delle buone pratiche di security by design e by default. Alla aziende, alle PA si chiederà un nuovo sforzo di cambio di mentalità e un forte impegno nello studio di soluzioni sostenibili e intelligenti per promuovere il progresso, la tecnologia, lo sviluppo e la sicurezza.
In tale ottica e con gli attuali scenari presenti, l’asse della sicurezza si sta spostando da un punto di vista solo fisico ad un approccio olistico della cybersecurity.
La sicurezza fisica delle infrastrutture è fondamentale ma anche la sicurezza cibernetica non deve essere sottovalutata.
Un problema della cybersecurity è che questa non ha confini spaziali e temporali. Se devo compiere un furto fisico, devo per forza farlo sul posto, viene fatto una sola volta e da una sola entità. Un furto informatico invece, posso farlo da qualsiasi posto nel mondo, posso farlo più volte e possono esserci diversi attaccanti, posso compiere nello stesso tempo più furti su più soggetti.
Dott. Stefano. Gorla
Governance e Compliance Team leader InTheCyber, DPO Certificato 001 FAC Certifica.
Un detto che risale agli anni 1990 recitava:
Non si migliora ciò che non si misura.
Misurare è fondamentale perché ci fornisce indicazioni di cosa stiamo facendo, dove stiamo andando e come.
Per poter verificare la direzione e quindi instaurare un sistema di misura è necessario scegliere cosa misurare e le metriche necessarie.
Si possono utilizzare sistemi di misura automatici oppure utilizzare metodologie quali l’audit.
Un audit è un processo teso a verificare la conformità ad alcuni requisiti, definiti dall’organizzazione e/o dal contesto. Una guida all’audit è riportata dalla ISO 19011 (sulla conduzione generale delle verifiche ispettive), che riporta
3.1 audit: Processo sistematico, indipendente e documentato per ottenere le evidenze dell’audit (3.3) e valutarle con obiettività, al fine di stabilire in quale misura i criteri dell’audit (3.2) sono stati soddisfatti.
Anche la normativa per il trattamento dei dati personali richiede una valutazione dei sistemi.
L’articolo 29 del DLgs 196/03 recitava:
4) Il Responsabile effettua il Trattamento attenendosi alle istruzioni impartite dal Titolare il quale, anche tramite verifiche periodiche, vigila sulla puntuale osservanza delle disposizioni di cui al comma 2 e delle proprie istruzioni
Mentre il regolamento europeo sulla protezione dei dati 2016/679 riporta:
Considerando:
74) È opportuno stabilire la responsabilità generale del titolare del trattamento per qualsiasi trattamento di dati personali che quest’ultimo abbia effettuato direttamente o che altri abbiano effettuato per suo conto. In particolare, il titolare del trattamento dovrebbe essere tenuto a mettere in atto misure adeguate ed efficaci ed essere in grado di dimostrare la conformità delle attività di trattamento con il presente regolamento, compresa l’efficacia delle misure. Tali misure dovrebbero tener conto della natura, dell’ambito di applicazione, del contesto e delle finalità del trattamento, nonché del rischio per i diritti e le libertà delle persone fisiche.
81) Per garantire che siano rispettate le prescrizioni del presente regolamento riguardo al trattamento che il responsabile del trattamento deve eseguire per conto del titolare del trattamento, quando affida delle attività di trattamento a un responsabile del trattamento il titolare del trattamento dovrebbe ricorrere unicamente a responsabili del trattamento che presentino garanzie sufficienti, in particolare in termini di conoscenza specialistica, affidabilità e risorse, per mettere in atto misure tecniche e organizzative che soddisfino i requisiti del presente regolamento, anche per la sicurezza del trattamento. […]
Articolo 28 Responsabile del trattamento
- h) metta a disposizione del titolare del trattamento tutte le informazioni necessarie per dimostrare il rispetto degli obblighi di cui al presente articolo e consenta e contribuisca alle attività di revisione, comprese le ispezioni, realizzati dal titolare del trattamento o da un altro soggetto da questi incaricato. Con riguardo alla lettera h) del primo comma, il responsabile del trattamento informa immediatamente il titolare del trattamento qualora, a suo parere, un’istruzione violi il presente regolamento o altre disposizioni, nazionali o dell’Unione, relative alla protezione dei dati
La sicurezza dei dati e delle informazioni è un processo trasversale che riguarda tutta l’organizzazione.
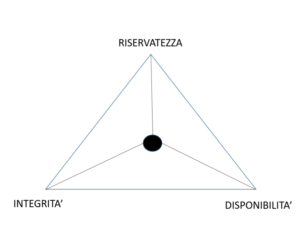
Valutare lo stato di questi sistemi risulta allora importante. Come accennato sopra è possibile fare ciò attraverso dei momenti formali, audit, svolti all’organizzazione oppure coinvolgendo il personale dedicata attraverso una metodologia di autovalutazione e di confronto. Sia per la parte audit che per la parte di autovalutazione, che deve essere guidata ed approfondita, si possono utilizzare vari modelli basati però tutti sui su tre punti fondamentali:
- Riservatezza
- Integrità
- Disponibilità
Ci sono vari livelli di autovalutazione in funzione di cosa vogliamo misurare e con quale dettaglio. Un esempio di una check list, di 15 punti, è riportato sotto, tratta dall’Italian Cybersucurity Report CIS Sapienza e laboratorio CINI del marzo 2017.
In questa autovalutazione è necessario definire però delle metriche e misurare la distanza (gap) o meglio l’applicazione del sistema di sicurezza IT.
Oltre alla guida sopra riportata esistono altri modelli che ci permettono, definendo dei livelli di applicazione, di autovalutare il sistema di sicurezza, confidando nell’onestà delle risposte degli interlocutori.
Uno dei modelli di riferimento si trova nell’allegato A della norma ISO 27001 (la SOA) e la ISO 27002 che guida con maggior dettaglio le richieste della SOA.
L’allegato A si compone di 114 domande suddivise nei seguenti capitoli:
- 5: Politiche per la sicurezza delle informazioni;
- 6: organizzazione della sicurezza delle informazioni;
- 7: Sicurezza delle risorse umane,
- 8: Gestione degli asset;
- 9: Controllo degli accessi
- 10: Crittografia;
- 11: Sicurezza fisica e ambientale;
- 12: Sicurezza delle attività operative;
- 13: Sicurezza delle comunicazioni;
- 14: Acquisizione, sviluppo e manutenzione dei sistemi;
- 15: Relazioni con i fornitori;
- 16: Gestione degli incidenti relativi alla sicurezza delle informazioni;
- 17: Aspetti relativi alla sicurezza delle informazioni nella gestione della continuità operativa;
- 18: Conformità.
La possibilità di poter seguire una lista molto complessa di 114 controlli suddivisi in 13 capitoli con i relativi sotto capitoli, facilita l’organizzazione nell’autovalutazione e nella gestione. Se un requisito non risulta soddisfatto, per implementare correttamente il sistema è necessario prevedere dei piani d’azione per soddisfarlo.
Per ognuna si stabilisce il grado di applicazione in modo da avere una fotografia dell’organizzazione.
Secondo la tabella proposta.
Si è utilizzato il CSF NIST, Cyber Security Framework NIST, per una autovalutazione dello stato del sistema organizzazione RIPORTARE DOMANDE
Se modello non copre introduzione di altre voci da altri modelli.
Per ogni domanda del framework sì è attribuito un valore all’applicazione del sistema riferito alle domande poste.
Un esempio è riportato sotto.
Per ogni asse viene poi eseguita la media dei valori così ottenuti, in modo da identificare lo stato aziendale.
Scritto da Alfredo Visconti Presidente ANDIP
_________________________________________________
Abrogate le misure minime di sicurezza previste dal D. lgs 196/2003, il GDPR per garantire un livello di sicurezza adeguato al rischio ha introdotto il criterio della pseudonimizzazione/anonimizzazione dei dati ossia la conservazione di informazioni di profilazione dell’utente atte da impedirne l’identificazione.
Come già detto con il GDPR si è abbandonato il concetto di sicurezza minima per affrontare la sicurezza sia fisica che logica all’interno di un concetto che raccomanda l’utilizzo di sistemi che consentano di anonimizzare o pseudonimizzare le informazioni che identificano una persona, nell’ottica della protezione dei dati
Nell’ottica nuova, rispetto al vecchio D.lgs 196/2003 (come detto misure minime allegato abrogato), tra le misure di sicurezza per la protezione dei dati personali, si raccomanda in modo forte e perentorio l’utilizzo di sistemi atti ad anonimizzare o pseudonimizzare le informazioni che identificano una persona.
Non stiamo parlando di fantascienza ma di tecniche o meglio di meccanismi il cui scopo è quello di ridurre i rischi connessi al trattamento di dati personali e contribuire a rendere i titolari/responsabili del trattamento conformi alle nuove regole sulla privacy.
Ma al fine di non ingenerare fraintendimenti è bene specificare da subito che stiamo parlano di due tecniche diverse per cui occorre una scelta oculata e cosciente per intraprendere una strada piuttosto che un’altra.
La pseudonimizzazione garantisce i dati sottoposti al trattamento di privacy, operando tecnicamente attraverso la sostituzione della la maggior parte dei campi identificabili contenuti all’interno di un record in cui sono presenti dati personali, con uno o più elementi mascherati o pseudonimi. Può essere usato ad esempio un unico pseudonimo riferito ad un insieme univoco di dati, ma anche un singolo pseudonimo per ogni specifico dato.
| Dati di produzione | Dati mascherati | ||||
| Nome | Cognome | Nome | Cognome | ||
| Alfredo | Visconti | vis@gmail.com | Aldo | Perti | per@gmail.com |
Il GDPR fornisce una definizione di pseudonimizzazione, spiegandola come il trattamento dei dati personali in modo tale che i dati personali non possano più essere attribuiti a un interessato specifico senza l’utilizzo di informazioni aggiuntive, a condizione che tali informazioni aggiuntive siano conservate separatamente e soggette a misure tecniche e organizzative intese a garantire che tali dati personali non siano attribuiti a una persona fisica identificata o identificabile.
Pertanto, in base a quanto stabilito dal Regolamento n.679, al fine di pseudonimizzare correttamente un insieme di dati occorre che le ulteriori informazioni che rendono quei dati attribuibili ad un soggetto specifico, consentendone dunque l’identificazione, siano conservate separatamente e soggette a misure tecniche e organizzative che garantiscano la non attribuzione a una persona identificata o identificabile.
Come detto è fondamentale capire che Pseudonimizzazione e anonimizzazione se pur simili nelle tecniche e nei risultati sono estremamente diverse, entrambe le tecniche, oscurano i dati personali, ma la pseudonimizzazione permette di identificare in un secondo momento i dati anche in maniera indiretta o da remoto, mentre i dati anonimi non consentono la successiva identificazione.
Riassumendo quindi con l’anonimizzazione, viene rimosso qualsiasi dato/valore riconoscibile che possa permettere di risalire ad un soggetto specifico identificandolo, di converso invece la pseudonimizzazione non elimina gli elementi identificativi dai dati, ma ne riduce il collegamento con il valore/identità originale ad esempio attraverso l’utilizzo della crittografia.
Nella scelta fra le due tecniche non vi sono particolari accorgimenti e/o consigli è importante invece identificare i dati che solo a titolo di esempio anche se non esaustivo, potrebbero essere::
- codici fiscali, partita iva;
- coordinate bancarie, IBAN;
- dichiarazioni di redditi;
- certificati medici
- fatture;
- dati genetici, dati sanitari, dati finanziari
- numeri di carte di credito;
- numeri di telefono;
- indirizzi
Esistono molte tecniche per la pseudonimizzazione del dato, la scelta deve essere la conseguenza di un serio lavoro di confronto tra costi e benefici, ben calato nella realtà produttiva in cui deve operare, perché uno studio di fattibilità sbagliato potrebbe anche comportare un oneroso carico sia economico si di lavoro fino a giungere eventualmente anche alla perdita dei dati stessi o meglio sarebbe dire fino a rendere il dato inutilizzabile.
Solo per citare qualche esempio si può operare sull’uso di chiavi d’accesso, funzioni di hash e token, se non si vuole alterare in alcun modo la struttura del set di dati è possibile selezionare le informazioni identificabili e usare la crittografia mediante l’impiego di una chiave d’accesso forte o una funzione di hash.
Cosi facendo le informazioni saranno opportunamente mascherate, protette e rese illeggibili e solo le persone che avranno a disposizione la chiave d’accesso (comunemente chiamata chiave di decrittografia) o la password potranno leggere il contenuto del file.
Un’altra tecnica è quella che impiega il token, che come ben sappiamo si usa solitamente per criptare i dati finanziari, essa si basa sull’impiego di un meccanismo di crittografia univoca o sull’assegnazione, tramite una funzione indicizzata, di un numero sequenziale o di un numero generato casualmente che non deriva esattamente dai dati originali.
Diverse invece sono le tecniche per l’anonimizzazione ed in tal caso possiamo parlare di:
- Correlabilità; stiamo parlando nello specifico di correlare appunto almeno due informazioni riguardanti una stessa persona o un gruppo di soggetti inseriti nella stessa banca di dati o in due diverse banche dati; mediante questa tecnica un soggetto non autorizzato potrebbe essere in grado di determinare (ad esempio mediante un’analisi della correlazione) che due informazioni sono assegnate allo stesso gruppo di persone, ma non riuscirebbe ad identificare alcuna persona del gruppo;
- rumore statico; oltre la correlabilità questa tecnica consiste nell’alterazione degli attributi contenuti in un set di dati in modo tale da renderli meno precisi, mantenendo allo stesso tempo la composizione generale. Nel momento in cui tratta il set di dati, l’osservatore presume che i valori attribuiti siano certi ed esatti, ma ciò corrisponde solo limitatamente al vero. Se la tecnica viene applicata in maniera efficace, eventuali terzi non riescono a identificare una persona né possono correggere i dati;
- Scrambling; tecnica che consente di offuscare le lettere dell’alfabeto mescolandole tra loro. A volte il processo può essere invertito.
Naturalmente, esistono molte altre tecniche con gradi di affidabilità differenti e molti software e aziende che forniscono servizi per effettuare la pseudonimizzazione o l’anonimizzazione del dato: utilizzandoli sui propri database questi software restituiscono un contenuto in cui i dati personali sono sostituiti da valori non correlati ai dati a seconda della tecnica impiegata. Vi sono alcuni software che consentono di essere installati sulle macchine, vengono concessi in licenza (alcuni sono opensource) e permettono di effettuare la conversione direttamente in house, senza passare per la rete Internet, permettendo così una maggiore protezione del dato e un più alto livello di sicurezza per l’adeguamento al GDPR di titolari e responsabili del trattamento.
Scritto da Alfredo Visconti Presidente ANDIP _____________________________________________________________
E’ bene partire da un assunto chiaro, il GDPR 679/2016 è denominato “Regolamento generale sulla Protezione dei dati”, il nostro D.lgs 196/2003 era ed è conosciuto come “Codice in materia di protezione dei dati personali”, si evince che ambedue hanno lo scopo di proteggere i dati (anche e forse soprattutto quando sono riferiti al business) e non di vietarne l’utilizzo.
Per quanto riguarda, il mondo del marketing e la gestione delle attività afferenti alle politiche di mail marketing, il GDPR non vieta in alcun modo questa prassi, in molti forse in troppi hanno cavalcato il concetto di divieto per poter tacciare il concetto di privacy e di tutela dei dati personali come lo strumento anti-business che avrebbe mortalmente colpito il mercato in nome di una difesa del consumatore, blanda e senza nessun presupposto valido.
Il vero problema che ci troviamo ad affrontare e che sarà di portata ancora maggiore con l’ingresso in vigore del nuovo registro delle opposizioni sta nel fatto che il mondo del marketing e lo stesso dicasi per le mail professionali, è stato gestito in modo decisamente poco serio, non essendo riusciti ad organizzare il momento con adeguata professionalità.
Il tutto ha portato ad un irrigidimento sia lato normativo, dove è prevalsa la convinzione che tutto si poteva fare se la mail era di pubblico dominio, sia lato mercato, dove l’utenza si è sentita assediata senza nessuna possibilità di uscita.
Del resto è bene ricordare che lo spam è sempre stato vietato o contrario ai termini di utilizzo della maggior parte dei provider di posta elettronica.
Comunque da questo primo passaggio emerge forte il concetto che in ambito privacy i dati si possono usare se adeguatamente protetti ed utilizzati attraverso opportuno rilascio di consenso
Tanto ciò detto per chiarire che il GDPR non vieta questa pratica ma ne “norma” la raccolta del consenso e quindi dell’utilizzo, richiedendo alle organizzazioni di chiedere un consenso affermativo per poter inviare comunicazioni, e subito dopo prevedendo in modo chiaro ed esplicito la possibilità di cambiare il consenso ed eventualmente di eliminare lo stesso.
Riassumendo per le pratiche di mail marketing è necessario
- Il consenso – che deve essere esplicito per quella determinata attività, quindi non generico
- La revoca – si deve rendere fruibile in modo semplice e diretto la possibilità di annullare il consenso
- La gestione – come per l’annullo si deve rendere possibile gestire e quindi eventualmente modificare il proprio consenso
In mancanza di questi tre elementi si viola apertamente il GDPR.
Quanto fin qui detto e scritto ricade almeno per la parte delle email marketing nel concetto di opt out e opt in che in questo caso specifico si differenziano in singol opt in e double opt in. Sono questi i termini informatici usati per prevenire lo spam essendo soprattutto allo stesso tempo in regola con le “norme” previste sulla privacy.
Questi concetti li troviamo espressi e spesso presenti nella gestione delle newsletter, ed è bene capire le differenze in termini di regole tra i due sistemi
Opt-Out
l’iscritto riceve le newsletter fino a quando, in modo esplicito, non dichiari di non voler ricevere più messaggi dalla lista, e fin tanto che non si esprime questo volere negativo o di cancellazione le email continueranno a viaggiare senza nessuna restrizione.
Single Opt-In
L’email marketing basato sul single Opt-In prevede un’iscrizione ad una lista che quindi a sua volta prevede un consenso esplicito del destinatario a ricevere quelle newsletter e/o comunicazioni via email o appunto newsletter. Nella pratica, corretta, il passaggio informatico avviene tramite una form di registrazione che però non prevede la verifica dell’indirizzi del destinatario, quindi è possibile ci si iscriva alla lista utilizzando una email di altri senza l’autorizzazione di queste;
Double Opt-in
Sistema che garantisce un livello di sicurezza maggiore, richiedendo non solo l’iscrizione, ma anche la conferma a tale iscrizione tramite una successiva email di notifica, cosi facendo si elimina il problema della falsa iscrizione visto in precedenza. Per nostra fortuna questo sistema ha preso piede e quindi nella tutela dei dati personali abbiamo raggiunto un livello molto più aderente alle regole del GDPR.
Ma lo scettro dello sfruttamento dei dati che viaggiano via mail, il marketing lo divide con le normali attività di posta elettronica, aprendo molti versanti relativi alla sicurezza dei dati completamente scoperti.
Forse non tutti ci siamo resi conto che quanto fin qui scritto rappresenta i principi di protezione dei dati stabiliti all’art. 5 che sono “liceità, correttezza e trasparenza”.
Volendo quindi riassumere è ormai chiaro che i dati si possono utilizzare solo se siamo in presenza e nel rispetto di adeguate giustificazioni legali ed il loro utilizzo deve essere basato su una comunicazione trasparente e inequivocabile con l’interessato, che ne abbia rilasciato opportuno e adeguato consenso.
Naturalmente non stiamo parlando in modo astratto, perché l’art. 6 ci spiega in modo specifico le “basi legali” per gestire, raccogliere, archiviare, utilizzare, … i dati delle persone, e naturalmente non si poteva non partire dal concetto del consenso che deve essere ottenuto in modo inequivocabile e dopo una chiara esplicazione completa di ciò che si intende fare con i dati. Quindi volendo riportare cose dette ridette ormai da tutti, specifichiamo che:
- Il consenso deve essere “liberamente dato, specifico, informato e inequivocabile”.
- Le richieste di consenso devono essere “chiaramente distinguibili dalle altre materie” e presentate in “un linguaggio chiaro e semplice”.
- Gli interessati possono revocare il consenso precedentemente prestato
- I minori di 13 anni possono dare il consenso solo previa autorizzazione dei genitori.
- È necessario conservare le prove documentali del consenso.
e dobbiamo tra le altre sicuramente aggiungere il “legittimo interesse”.
Tuttavia, come riportato direttamente dal Garante “in particolare l’art. 13 offre alle organizzazioni un altro modo di utilizzare i dati di una persona per scopi di marketing che deriva dalla base contrattuale. Nel contesto di una vendita di un bene o servizio, un’organizzazione “può utilizzare questi dati di contatto elettronici per la commercializzazione diretta di propri prodotti o servizi simili a condizione che ai clienti sia data in modo chiaro e distinto la possibilità di opporsi, gratuitamente e in modo semplice”, secondo l’articolo 13, parte 2. In sostanza, ciò significa che un’organizzazione può inviarti legalmente e-mail di marketing sul servizio che ti fornisce purché ti informi che puoi rinunciare in qualsiasi momento e che vi sia il possibilità di disiscriversi in ogni comunicazione.”
Cominciamo a non pensare in modo univoco ai messaggi ma cerchiamo di capire in quale mondo un messaggio inviato va a finire, quanti lo leggono e di conseguenza quanti lo possono usare, ma soprattutto rendiamoci conto che in assoluto oggi quando si parla di dato sarebbe più corretto parlare di dati in movimento. Volendo fare un esempio esplicativo ma non esaustivo dell’ampia tematica che stiamo aprendo basti pensare ad un semplice messaggio di posta che una volta inviato viene ricevuto almeno su:
- Pc di lavoro
- Portatile
- Tablet/i-pad
- Smartphone
Creando quindi una proliferazione del dato e dell’informazione su cui difficilmente si può operare un serio controllo di protezione. Se agli esempi appena fatti aggiungiamo poi che molto spesso un messaggio viene inoltrato o gestito tramite minimo
- social network
capite da soli che la protezione diventa un algoritmo protettivo da vero esperto informatico, in quanto in questo giro, ripeto veramente minimale, il dato e l’informazione che porta con se si è salvato da più parti e su più supporti aprendo una fonte d’attacco molto ampio per prelevarli.
A questo problema si può ovviare attraverso il rispetto del GDPR e l’osservanza delle necessarie regole aziendali, quindi come contrasto avremo sicuramente
Una metodologia di consultazione e conservazione che deve essere opportunamente edotta ai dipendenti avendo da una parte la consultazione che esplicita le regole con cui si scaricano le mail e dall’altro affronta le regole della cancellazione di questo mondo di dati.
La cancellazione dei dati è una parte importante del GDPR, e delle tecniche di protezione, più volte richiamata e sulla quale il Garante ha posto una attenzione notevole, fino a chiedere che i termini di cancellazione dei dati fossero dichiarati nell’informativa pubblica e come campo obbligatorio nel registro del trattamento. La conservazione è un principio di protezione dei dati, esplicitato all’articolo 5, lettera e), dove si afferma che i dati personali possono essere conservati per “non più di quanto necessario per le finalità per le quali i dati personali sono trattati”. Sempre il concetto di cancellazione viene poi ripreso anche all’art. 17 dove è normato il principio all’oblio aprendo una grossa problematica sul concetto di cancellazione e deindicizzazione quando il dato è presente anche sul mondo internet.
Certo diciamoci la verità questo della cancellazione è uno scoglio molto duro, perché quasi esclusivamente culturale, e sicuramente è più facile che un cammello passi per la cruna di un ago, piuttosto che qualcuno di noi (me compreso) cancelli una mail ritenuta “fondamentale”.
Non si cancellano la mail per svariato motivi e per le più raffinate raccomandazioni, ma dobbiamo far conto con la problematica per cui più dati si conservano, maggiore sarà la responsabilità in caso di violazione.
Per altro ricordiamoci che la cancellazione dei dati personali non necessari è ora richiesta dalla legge europea. Secondo il GDPR, dovremo rivedere periodicamente la politica di conservazione della posta elettronica con l’obiettivo di ridurre la quantità di dati e di informazioni che archiviamo. Il regolamento richiede di dimostrare di avere una politica in atto che bilancia i legittimi interessi commerciali con i gli obblighi di protezione dei dati ai sensi del GDPR.
Sia ben chiaro nel GDPR, non viene espressamente indicato per quanto tempo le società devono conservare le e-mail, pertanto, come già detto in precedenza, spetta alle organizzazioni creare le proprie policies e dimostrare che è stata, di conseguenza, implementata una metodologia specifica, anche perché le novità apportate dal Regolamento Europeo n. 679/2016 sulla protezione dei dati personali vi è l’esplicita previsione del divieto di conservare gli stessi per un tempo superiore a quello necessario al perseguimento dello scopo del trattamento.
Se vogliamo un riferimento pseudo normativo potremmo dire che il trattamento dei dati personali delle persone fisiche è sempre stato improntato ai principi di necessità e finalità del trattamento, secondo i quali i dati raccolti non possono essere trattati per un tempo ulteriore rispetto a quello strettamente necessario allo scopo della raccolta stessa.
Quanto appena scritto non può che tradursi nell’obbligo per il titolare del trattamento di provvedere alla cancellazione dei dati raccolti una volta perseguito lo scopo, non potendo essere conservati per periodi ulteriori, infatti l’art. 5, comma 1, lett. e), del GDPR cita che i dati personali devono essere “conservati in una forma che consenta l’identificazione degli interessati per un arco di tempo non superiore al conseguimento delle finalità per le quali sono trattati”.
In un solo caso il GDPR consente di trattenere i dati per periodi più lunghi di quelli strettamente necessari, quando i dati sono trattati esclusivamente a fini di archiviazione nel pubblico interesse, di ricerca scientifica o storica o a fini statistici, previa attuazione di adeguate misure tecniche e organizzative a tutela dei diritti e delle libertà dell’interessato (cd. principio di “limitazione della conservazione”).
Naturalmente nel perimetro della sicurezza della posta non possiamo pensare solo alla gestione delle procedure di cancellazione, ma dobbiamo porre l’accento anche su tecniche informatiche importanti ed esistenti da sempre, stiamo parlando di crittografia, anonimizzazione, pseudonimizzazione, dati sintetici di ci abbiamo già scritto in un precedente articolo, e tutte le classiche casistiche di attacco ormai conosciute dai più ma che ancora danno risultati importanti.
Il novantuno percento degli attacchi informatici inizia con un’e-mail di phishing, attraverso la quale si tenta di accedere a un account o dispositivo utilizzando l’inganno o il malware, in questi casi, o comunque nel dubbio, si tenga sempre presente che è buona norma che collegamenti e allegati da account sconosciuti non debbano mai essere cliccati o scaricati, perché diversamente si potrebbe ottenere l’accesso a un account o dispositivo, dal quale è possibile accedere ad altri dispositivi e alla rete, con il risultato che un errore umano potrebbe compromettere grandi quantità di dati.
Per evitare responsabilità, e sanzioni è importante educare alla sicurezza della posta elettronica, anche e soprattutto scrivendo le policies opportune per la gestione. Una buona procedura di policies aziendali per la gestione della posta deve assolutamente prevedere ad esempio una regola che imponga di non aprire mail sospette se non con l’autorizzazione del titolare o dell’amministratore di rete
Con il termine Crittografia o Cifratura si intende il processo volto a impedire la leggibilità in chiaro di un testo a chi non abbia il sistema di cifratura e la chiave per decifrare il testo stesso e nel nostro mondo l’articolo 32 del Regolamento UE 2016/679 relativo alla Sicurezza del Trattamento recita
“1. Tenendo conto dello stato dell’arte e dei costi di attuazione, nonché della natura, dell’oggetto, del contesto e delle finalità del trattamento, come anche del rischio di varia probabilità e gravità per i diritti e le libertà delle persone fisiche, il Titolare del trattamento e il Responsabile del trattamento mettono in atto misure tecniche ed organizzative adeguate per garantire un livello di sicurezza adeguato al rischio, che comprendono, tra le altre, se del caso:
- a) la pseudonimizzazione e la cifratura dei dati personali”
Il Regolamento non entra nel dettaglio di quando applicare la misura (infatti il testo preciso è: “che comprendono, tra le altre, se del caso”), né specifica quale livello o metodologia di cifratura applicare; si limita semplicemente ad indicare una misura che è molto importante e significativa in un sistema di protezione dei dati. Questo in perfetto accordo al principio cardine del Regolamento che prevede che sia il Titolare del trattamento a valutare quali misure di sicurezza adottare per proteggere i dati trattati (Responsabilità del Titolare, nel testo originale Accountability).
Abbiamo già detto che l’attuale quadro normativo, affida al titolare il compito e la responsabilità di decidere quali misure di sicurezza possano e devono essere considerate idonee al fine di garantire un’adeguata protezione ai dati personali trattati. In questo ambito decisionale il mercato ha deciso di considerare la cifratura quale misura specifica e forte per garantire riservatezza, integrità e disponibilità dei sistemi e dei servizi di trattamento.
Infatti all’interno del testo del Regolamento UE, il concetto di cifratura viene spesso citato basti pensare al Considerando 83 ove è previsto che i titolari o i responsabili del trattamento dovrebbero valutare i rischi delle loro varie attività di trattamento dei dati e attuare misure per mitigare tali rischi, come la cifratura, in modo da:
- mantenere la sicurezza;
- impedire trattamenti non conformi al GDPR
contestualmente l’art. 32, annovera la cifratura tra le misure tecniche e organizzative a disposizione del titolare, per garantire un livello di sicurezza adeguato al rischio, e l’art. 34, focalizzato sulla comunicazione di un’eventuale violazione di dati ai soggetti interessati, menziona nuovamente la cifratura come esimente per il titolare che abbia implementato misure adeguate a rendere i dati, oggetto della violazione, incomprensibili a chiunque non sia autorizzato ad accedervi.
In linea generale, possiamo dunque considerare questo come uno strumento certamente utile ma, di certo, non l’unico da implementare. Pur non essendo una misura “obbligata”, rimane comunque “caldamente consigliata” per limitare i rischi impattanti sui dati personali. Il ricorso alla cifratura viene dunque rimesso all’iniziativa dei titolari del trattamento, in forza di quel principio di accountability che sta alla base del nuovo approccio promosso dalla normativa.
Dopo la cifratura o crittografia vediamo brevemente la pseudonimizzazione che è: il trattamento dei dati personali in modo tale che i dati personali non possano più essere attribuiti a un interessato specifico senza l’utilizzo di informazioni aggiuntive, a condizione che tali informazioni aggiuntive siano conservate separatamente e soggette a misure tecniche e organizzative intese a garantire che tali dati personali non siano attribuiti a una persona fisica identificata o identificabile; è una misura che da un punto di vista informatica non offre un grande livello di sicurezza, anche perché chi dovesse accedere ai dati avrebbe comunque la visibilità di una parte dell’intero set di dati, mentre la crittografia o cifratura è sicuramente molto più performante in termini di sicurezza informatica.
Scritto da Avv. Cristina Mantelli __________________________________________
Le nostre e-mail contengono molto spesso dati personali. Durante il loro percorso verso il destinatario tali comunicazioni sono gestite da diversi enti, nodi e fornitori di servizi che possono intercettare, manipolare e utilizzare illegalmente il loro contenuto. Al fine di ridurre questi rischi, l’articolo 32 del GDPR e i considerando collegati[i] chiedono ai responsabili del trattamento di attuare misure di sicurezza adeguate. Se tali standard non sono soddisfatti, la riservatezza e l’integrità delle nostre comunicazioni rischiano seriamente di essere violate.
Come fare quindi per ridurre i rischi? È vivamente consigliato utilizzare programmi di crittografia.
Infatti inviare email non crittografate può comportare diversi rischi: uno di questi, molto diffuso oggi, oltre ai recenti paventati rischi cyber determinati dalla situazione ucraina, è la frode informatica denominata “the man in the mail” o “the man in the middle”. La frode consiste nell’intercettare la mail con la quale un venditore/professionista/artigiano invia in allegato al cliente la fattura o un altro documento commerciale, contenente i dettagli del conto corrente su cui effettuare il pagamento di un servizio o di un bene. L’hacker, in quello stesso momento, interviene per sostituirlo con il proprio codice IBAN: a questo punto, l’ignara vittima esegue il bonifico non sul conto corrente indicato, ma su quello del truffatore che svuota così il conto corrente con una serie di bonifici su conti esteri.
Quindi come possiamo proteggerci dalle truffe online? Con un sistema di crittografia.
Uno tra i più conosciuti si chiama open PGP (Pretty Good Privacy) fruibile liberamente da tutti poiché è un protocollo di “crittografia a chiave pubblica”.
PGP si basa sulla generazione di una coppia di chiavi: una “segreta” (o “privata”) e l’altra “pubblica”. L’utente tiene al sicuro la propria chiave segreta mentre diffonde e rende disponibile la chiave pubblica. Quindi così facendo si otterranno due risultati:
- La riservatezza del contenuto: il messaggio viene crittografato e reso illeggibile per un terzo che non possegga le chiavi;
- L’autenticità del mittente: la chiave pubblica di Caio (che è stata precedentemente inviata a Sempronio) potrà combaciare solo con la sua chiave privata. Questa funzione ci dà la certezza della provenienza del messaggio.
Per poterlo utilizzare ci sono molti software adatti ai diversi sistemi operativi. Il sito ufficiale di OpenPGP e quello di GnuPG indicano quali sono i software che utilizzano tale protocollo. Di seguito sono riportati quelli principali:
- Gpg4win (per Windows /Outlook)
- GPGTOOLS (per macOS)
- Enigmail (per il client di posta Thunderbird)
- OpenKeychain (per Android)
- iPGMail (per iOS)
Riepilogando, se teniamo conto delle responsabilità, dei rischi in gioco e del contenuto delle informazioni che trasmettiamo è più che mai opportuno adottare la crittografia quale strumento di sicurezza delle nostre mail, perlomeno di quelle che contengono dati sensibili.
[i] (83) Per mantenere la sicurezza e prevenire trattamenti in violazione al presente regolamento, il titolare del trattamento o il responsabile del trattamento dovrebbe valutare i rischi inerenti al trattamento e attuare misure per limitare tali rischi, quali la cifratura. Tali misure dovrebbero assicurare un adeguato livello di sicurezza, inclusa la riservatezza, tenuto conto dello stato dell’arte e dei costi di attuazione rispetto ai rischi che presentano i trattamenti e alla natura dei dati personali da proteggere. Nella valutazione del rischio per la sicurezza dei dati è opportuno tenere in considerazione i rischi presentati dal trattamento dei dati personali, come la distruzione accidentale o illegale, la perdita, la modifica, la rivelazione o l’accesso non autorizzati a dati personali trasmessi, conservati o comunque elaborati, che potrebbero cagionare in particolare un danno fisico, materiale o immateriale.
SCRITTO DA ALFREDO VISCONTI PRESIDENTE ANDIP
________________________________________________________
Negli anni, finalmente, le aziende hanno capito, o purtroppo molto più spesso, si sono adeguate al dettame per cui il patrimonio più importante, e da tutelare, nelle aziende sono i dati che le stesse aziende nel tempo hanno acquisto e fatti propri ma soprattutto li hanno plasmati sul proprio business.
Qualcuno oggi dice che finalmente nelle aziende si rispettano gli investimenti in macchine, uffici di rappresentanza risorse interne ed altro, ma finalmente i dati hanno acquisito centralità nel business e nella produttività, ma cosa ancora più importante sono diventati qualcosa di tangibile, migrando dal concetto di dato al concetto molto più evoluto ed importante di informazione.
Oggi le società, che sono obbligate a lavorare con i dati e con le informazioni che ne derivano, incontrano costantemente barriere, imputabili in modo specifico sia alla tecnologia e quindi alla propria struttura tecnica sia in base all’ordinamento giuridico.
Questi ostacoli si traducono in mancate opportunità di crescita e possono ostacolare l’innovazione del prodotto ma allo stesso tempo hanno generato la paura della condivisione di dati soprattutto se sono sensibili con partner, potenziali clienti, o prospect esterni.
Diamo atto che questo grande passaggio da dato ad informazione è da imputarsi anche all’evoluzione del concetto di privacy.
Già con il nostro D.lgs 196/2003 ma ancor di più con l’entrata in vigore del regolamento generale sulla protezione dei dati personali UE 2016/679 si è generato un cambio di passo rispetto alla gestione delle informazioni sensibili e della loro messa in sicurezza.
Il regolamento infatti si lascia alle spalle un primo approccio marcatamente formalistico e spesso solo burocratico completamente basato su regole analiticamente definite, nel nostro passato nell’allegato b al decreto appena citato, il famoso “elenco delle misure minime di sicurezza da adottare”.
Ad oggi la normativa sancisce il passaggio ad un approccio che responsabilizza maggiormente il Titolare del Trattamento, con il GDPR si sono ampliati i diritti dell’interessato in tema di trattamento dei dati personali e sensibili, offrendo linee guida sicuramente meno interpretabili e che prevedono, solo a titolo di esempio non esaustivo, il diritto all’oblio ma soprattutto impongono precise limitazioni, attraverso indicazioni, come ad esempio adottare una soluzione di Continuous Vulnerability Assessment che permette di garantire l’efficienza e la sicurezza di tutti i sistemi che raccolgono, archiviano e gestiscono dati personali in maniera conforme al GDPR.
Dal punto di vista della governance, tenendo conto dello stato dell’arte e dei costi di attuazione, nonché della natura, dell’oggetto, del contesto e delle finalità del trattamento, le aziende sono tenute a mettere in atto misure tali da garantire un livello di sicurezza e di riservatezza adeguato al rischio (art. 32). L’analisi dei rischi viene richiesta almeno per (art. 35):
- l’utilizzo di soluzioni tecnologiche che elaborano una valutazione sistematica e globale di aspetti personali relativi a persone fisiche, attraverso modalità di trattamento automatiche (compresa la profilazione, sulla quale vengano prese decisioni che hanno risvolti giuridici o che impattano significativamente su dette persone fisiche: situazione economica, salute, preferenze personali, localizzazione, profili per il marketing);
- trattamenti su larga scala di dati sensibili e/o giudiziari (ad esempio numero di persone coinvolte, volume di dati trattati, permanenza dei dati trattati, estensione geografica del trattamento, trasferimento di dati in Paesi non appartenente all’Unione europea) o dati di persone con maggiore necessità di protezione (es. bambini, pazienti con malattie mentali);
- sorveglianza sistematica su larga scala di una zona accessibile al pubblico.
Tuttavia, le aziende e i ricercatori, che mirano ad accedere a questi dati per sviluppare algoritmi o sistemi di machine learning, non necessariamente devono accedere a dati strettamente reali, ma devono poter accedere a set di dati realistici che simulano e mantengono le stesse proprietà statistiche dell’informazione reale. Questi dati alternativi sono noti come dati sintetici.
I dati sintetici sono dati, o il loro risultato, creati attraverso una particolare tecnica di anonimizzazione basata su modelli di machine learning di tipo generativo. Partendo da un set di dati reali, si allena un sistema di intelligenza artificiale istruito a individuare le correlazioni e metriche statistiche del dataset originale, per poi generare un set di dati ex novo che mantiene la stessa distribuzione statistica del dataset originale, pur non condividendo alcun dato del dataset reale.
Questa tecnica detta appunto tecnica della sintetizzazione fa si che si possa risalire al dato reale dal dato generato, senza perdere l’informazione statistica originale, esattamente l’opposto di quanto succede sui dati con le normali tecniche di anonimizzazione, dove il dato è privato di tutti gli elementi “personali”. Ottimo risultato, l’anonimizzazione, ma cosi facendo si perdono e non si recuperano parte delle informazioni contenute nel set di dati.
I dati sintetici hanno diversi vantaggi, quali:
- il superamento delle restrizioni di utilizzo dei dati: i dati reali spesso nel loro utilizzo incontrano vincoli di utilizzo basati sulla disamina del GDPR, perchè i dati sintetici duplicano le proprietà statistiche fondamentali per l’utilizzo del dato ma sempre senza esporre i dati reali;
- la generazione di dati sintetici è a regime più economica rispetto all’acquisizione di dati reali;
- la condivisione e quindi la divulgazione a terzi delle informazioni viene resa possibile dalla natura statistica delle informazioni, che non porta con se la possibilità di accoppiare l’informazione ad una persona.
I dati sintetici rappresentano una soluzione tecnologica che incomincia a trovare una strada specifica soprattutto in alcuni settori come:
- le assicurazioni, i servizi bancari/finanziari ed il retail, settori in cui la data science e data analytics stanno già da tempo offrendo nuovi modi di lavorare sui dati, soprattutto quando questi devono essere esposti al pubblico;
- l’healthcare, mercato dove i dati sensibili, genetici, biometrici, ma sanitari in generale, godono di un regime di protezione normativa molto complicato;
- la Pubblica Amministrazione, settore dove la mole di dati detenuta è veramente importante sia in termini quantitativi sia sin termini qualitativi il cui valore informativo non sempre può essere reso disponibile al pubblico.
Chi progetta sistemi generativi di dati sintetici trova il giusto rapporto tra privacy e utilità, però dobbiamo sempre ricordare che non esistendo un collegamento diretto tra il dato reale e quello sintetico, non sarà mai possibile identificare il singolo dato originale analizzando gli attributi del dato generato.
Questa tecnica, che è giusto dire in tanti stanno studiando ed affinando anche nelle proprie aziende, ci permette di pensare che un sistema di sintetizzazione dei dati debba necessariamente essere valutato in base all’integrità del proprio modello generativo, piuttosto che sulla base del principio di minimizzazione dei dati, di cui agli artt. 5 e 6 GDPR.
I dati sintetici vengono creati in modo programmatico con tecniche di machine learning. È possibile utilizzare tecniche di machine learning classiche come gli alberi decisionali, così come le tecniche di deep learning . I requisiti per i dati sintetici influenzeranno il tipo di algoritmo utilizzato per generare i dati. Gli alberi decisionali e modelli di machine learning simili consentono alle aziende di creare distribuzioni di dati multimodali non classiche, addestrate su esempi di dati del mondo reale. La generazione di dati con questi algoritmi fornirà dati altamente correlati con i dati di addestramento originali.
I metodi basati sull’apprendimento profondo per la generazione di dati sintetici fanno in genere uso di un autoencoder variazionale (VAE) o di una rete di antagonismo generativo (GAN) . I VAE sono modelli di apprendimento automatico non supervisionati che fanno uso di codificatori e decodificatori. La parte del codificatore di un VAE è responsabile della compressione dei dati in una versione più semplice e compatta del set di dati originale, che il decodificatore analizza e utilizza per generare una rappresentazione dei dati di base. Un VAE viene addestrato con l’obiettivo di avere una relazione ottimale tra i dati di input e output, in cui sia i dati di input che i dati di output sono estremamente simili.
Quando si tratta di modelli GAN, vengono chiamate reti “antagoniste” poiché i GAN sono in realtà due reti che competono tra loro. Il generatore è responsabile della generazione dei dati sintetici, mentre la seconda rete (il discriminatore) opera confrontando i dati generati con un dataset reale e cerca di determinare quali dati sono falsi. Quando il discriminatore rileva dati falsi, il generatore ne viene informato e apporta modifiche per cercare di ottenere un nuovo batch di dati dal discriminatore. A sua volta, il discriminatore diventa sempre più bravo a rilevare i falsi. Le due reti sono addestrate l’una contro l’altra, con i falsi che diventano sempre più realistici.
Volendo citare qualche azienda che sui dati sintetici ha investito con competenza possiamo partire dai report di Gartner che cita:
Aindo come fornitore di dati sintetici all’interno del loro rapporto “Innovation Insight for Synthetic Data”. L’articolo afferma: “I dati sintetici possono essere un supplemento o un’alternativa efficace ai dati reali, fornendo accesso a dati annotati per costruire modelli di intelligenza artificiale accurati ed estensibili”.
Per chi vuole approfondire Aindo attraverso INTUITE.AI, rende disponibile la tecnologia dei dati sintetici sui prodotti.